La Lettre d'Alex N°4
Avril 2014
Révision
Gestion des Logs
Log of Interest
Person of Interest

Novice
Notion de base à connaître.
Novice
Notion de base à connaître.
Depuis l’origine de l’informatique, l’exécution d’un programme s’est toujours accompagnée de la génération de fichier trace sous forme tout d’abord d’un télétype qui imprimait sur papier le suivi de toutes les actions qui se déroulaient sur l’ordinateur mono-tâche.
Les Ordinateurs ont alors évolué devenant multitâches puis multisessions. Les traces d’exécutions se sont alors spécialisées :
- Les traces systèmes qui suivent le déroulement et les alertes des différents composants logiciels et matériels aussi appelé syslog.
- Les traces de sécurité qui suivent les actions de chaque utilisateurs sur un système utmp et wtmp qui effectue ce que l’on appelle du logging.
- Les traces applicatives, qui pour chaque programme, suivant le choix des développeurs, consignent le déroulement de son programme, logiciel ou progiciel.
Dans les entreprises ces différents logs sont la responsabilité de différentes équipes :
- Administrateurs systèmes.
- Equipe responsable de la sécurité informatique.
- Equipe d’exploitation de l’application.
Ces différents logs sont exploités dans différents contextes :
- Surveillance proactive par le suivi des warning
- Détection d’incidents
- Analyse des causes d’un incident.
Mais peuvent aussi être détournés pour générer de la communication entre progiciel, faire de la métrologie, ou mesurer la qualité de service.

Avancé
Pour ceux qui veulent aller pluis loin.
Aujourd’hui, nous vivons une complexification à outrance des infrastructures :
- Le serveur physique héberge un ou plusieurs serveurs logiques par la méthode du partitionnement.
- Chaque serveur logique peut contenir plusieurs serveurs virtuels, chacun avec son propre système d’exploitation.
- Chaque serveur virtuel héberge de nombreux logiciels qui peuvent s’exécuter dans une jvm (machine virtuelle Java) dédiée.
Chacune de ces couches matérielles ou logicielles possède ses propres logs.
Une seule application peut maintenant faire appel à de multiples couches applicatives et en même temps être répartie sur des dizaines de serveurs. Dans ce cas le responsable d’une application a la mission quasi impossible de maintenir cet ensemble en état de marche dans cette tour de Babel, car en plus chaque couche applicative et chaque type de matériel aura son propre format de log et son propre mode d’horodatage.
De là intervient le besoin d’un outil ou plutôt d’un ensemble d’outils permettant à terme :
- De suivre les logs
- De naviguer dans les logs
- De rechercher
- …
- De suivre des comportements
- De prédire des évènements
- De lutter contre des comportements
Mais cela c’est le rôle de la SIEM (Security Information and Event Mangement) et de progiciel tel SPLUNK, IBM/QRadar et HP ARCSIGHT ESM.



Mais pour le reste il existe des solutions payantes et d’autres gratuites ou presque, et même mieux open source. L’une de ces solutions open source est l’écosystème ELK (ElasticSearch, Logstash, Kibana).

Expert
Connaissances plus avancées pouvant surprendre même un expert.
1) D’abord Il faut récupérer et envoyer la log : pour les équipements connectés sur le réseau il faut d’abord les centraliser via un listener Syslog comme syslog-ng ou un listener de trap SNMP (pour les serveurs on peut utiliser directement Logstash) puis il faut encapsuler la donnée avant de l’expédier, une structure Json (c’est le format des documents Java) élémentaire est alors constituée : timestamp, host, path, type et le message proprement dit, c’est la fonction de Shipper.
![]()


{
"message": "Apr 14 05:09:13 serveur raslogd: 2014/04/21-05:00:53, [SEC-1203], 36583,, INFO, serveur, Login information: Login successful via TELNET/SSH/RSH. IP Addr: xxx.yyy.zzz.ttt",
"@timestamp": "2014-04-14T03:09:14.087Z",
"type": "brocade",
"host": "indexeur",
"path": "/var/log/remote.log",
}
2) Ensuite il faut résister à la pression, stocker et distribuer le travail, c’est le rôle de Redis (il est utilisé comme centre de tri, mais en fait c’est une base de données clé/valeur) ou RabbitMQ, c’est le rôle de Broker.


3) Il faut après enrichir et uniformiser (notamment pour leur horodatage) les logs collectés c’est le rôle de Logstash et son univers de modules extensible et personnalisable et notamment son acolyte Grok, c’est la fonction d’Indexer.
![]()
{
"message": "Apr 14 05:09:13 serveur raslogd: 2014/04/21-05:00:53, [SEC-1203], 36583,, INFO, serveur, Login information: Login successful via TELNET/SSH/RSH. IP Addr: xxx.yyy.zzz.ttt",
"@timestamp": "2014-04-14T03:09:14.087Z",
"type": "brocade",
"host": "indexeur",
"path": "/var/log/remote.log",
"clust": "prod",
"idx": "aoss",
"NHOST": "serveur",
"NPROCESS": "raslogd",
"MESSCAT": "SEC-1203",
"MESSID": "36583",
"SWseverity": "INFO",
"SWHOST": "serveur",
"SWMESS": "Login information: Login successful via TELNET/SSH/RSH. IP Addr: xxx.yyy.zzz.ttt",
"TIMESTAMP": "2014-04-14T05:09:13.000+02:00",
"EVT_TIMESTAMP": "2014-04-21T05:00:53.000+02:00",
"DOMAINE": "inet",
"TYPEDOMAINE": "com"
}
4) Il faut un bibliothécaire qui indexe, stocke, distribue, sécurise, recherche et suit la croissance des logs aussi souple et rapide que possible, il s’agit d’une base de données in memory qui en plus fait de l’indexation full texte : ElasticSearch, c’est la fonction de Search and Storage. Pour réaliser toutes ces fonctions Elasticsearch regroupe ces données sous formes d’index quotidiens, qu’il découpe en shard pour donner de la performance en lecture et écriture, et en réplicat afin de lui donner robustesse et proximité. Par ailleurs il peut fonctionner soit comme un serveur unique, soit en cluster applicatif avec croissance du nombre de nœuds à chaud, soit comme un service dans le Cloud.



5) Il faut des modules d’interrogation en mode ligne (Elasticsearch) ou d’interrogation avec un GUI souple et personnalisable Kibana, c’est la fonction de Web Interface



|
|
|
|
|
|
|
|
|
|
|
|
6) Il faut une console de supervision et d’administration, il existe depuis plusieurs années de nombreux modules pour ce rôle, je n’en garderai que 3 : ElasticsearchHQ (pour l’administration du cluster Elasticsearch) et Paramedic (pour la surveillance et le monitoring jusqu’au plus bas niveau du Shard) avant de parler du dernier né cette année, qui est développé par la même équipe qu'Elasticsearch et Kibana et qui s’appuie sur les mêmes composants : arrivé en début d’année, le merveilleux, le surprenant Marvel (pour un monitoring historisé jusqu’au plus fin détai).
![]() Marvel
Marvel
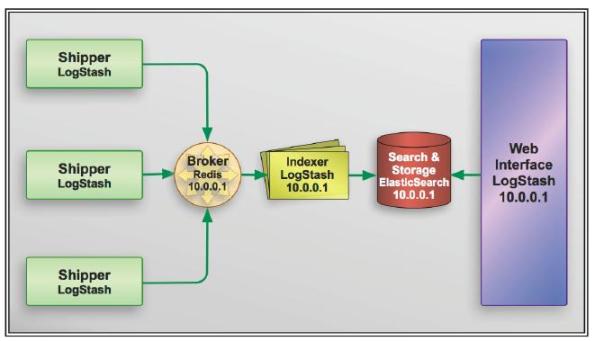
Bilan : Avec tout cela on a tout pour suivre les logs mais aussi pour construire l’essentiel d’une application personnalisable par l’utilisateur sans développement ou presque.
![]()
Enfin un dernier module dont je n’ai pas encore parlé car il n’est disponible dans sa version GA que depuis le 27/05/2014, ES for Hadoop qui donne à ElasticSearch l’accès au stockage Hadoop en plus d’EC2 et Amazon mais aussi les recherches en temps réel aux différents composants Hadoop : (Map/Reduce, Hive, Pig et Cascading)

Il existe déjà 3 services d’indexation ElasticSearch dans le Cloud :
- ![]() Bonsai.io : qui propose un service avec facturation au mois en fonction du volume et type de stockage choisi qui est le service en ligne de la société Elasticsearch.
Bonsai.io : qui propose un service avec facturation au mois en fonction du volume et type de stockage choisi qui est le service en ligne de la société Elasticsearch.
-  Qbox.io : qui propose un service avec facturation à l’heure ou au mois en fonction de la capacité RAM, du volume et type de stockage choisi.
Qbox.io : qui propose un service avec facturation à l’heure ou au mois en fonction de la capacité RAM, du volume et type de stockage choisi.
- ![]() Found.no : qui propose un service à l’heure ou au mois en fonction du nombre de Datacenter, du volume et type de stockage choisi.
Found.no : qui propose un service à l’heure ou au mois en fonction du nombre de Datacenter, du volume et type de stockage choisi.